

CONTEXT GRAPH
What agents need to know
Hire a world-class data engineer on Monday and they won't ship anything meaningful for weeks. They have to learn the warehouse. They have to learn why someone built fct_revenue the way they did. They have to learn which dashboard the CFO actually looks at on Friday mornings. The skill arrived on day one. The context did not.
Now turn on an agent. Same problem. Worse outcome, because the agent does not pause when it doesn't know something. It just acts, confidently, at machine speed.
That is what the Context Graph fixes.
DECISION MEMORY
Auto-extracts ADRs from every merged PR. We looked at 1,000+ production dbt models. 42% of PRs describe what changed but not why. That gap is where agents make expensive mistakes. Decision Memory closes it. After six months on the platform: 500+ decision traces. Call it three senior engineers' worth of institutional knowledge, available to every agent that asks.
TECHNICAL METADATA & COST INTELLIGENCE
Cost profiles per entity. Cross-platform lineage across dbt, Snowflake, Databricks, Airflow, and GitHub. Incident history. 85% accuracy on cost optimization. 30 to 50% documented savings on real customer workloads.
BUSINESS METADATA
Ownership, PII / SOX / GDPR classification, retention policies. Here's the difference it makes. A normal guardrail sees a column tagged "PII" and stops. A guardrail with business metadata knows that column feeds the CFO's quarterly close dashboard and was classified under SOX two years ago. One of those agents is safer than the other.
GOVERNANCE
What agents can't do wrong
Here's the thing about confident machines. They don't pause when they're wrong. They just go faster.
A junior engineer about to drop a production table will hesitate. They'll Slack someone. They'll wait. An agent will not. The agent reads the prompt, decides it has enough context, and ships. Sometimes it's right. Sometimes it costs you $40,000 in Snowflake credits before lunch.
Governance is the layer that makes agents pause. Not by slowing them down, but by giving them the same instinct a good engineer has: know what this will cost, know what it will break, know when to ask.
GUARDRAILS
Pre-execution cost checks built on three years of Fortune 500 query patterns. Blast radius analysis across downstream models, dashboards, PII columns, and incident history. The agent knows what the change will cost and what it will break, before it runs the change. Not after.
VALIDATION & REASONING TRACES
Every agent action leaves a paper trail. Cost estimate, blast radius, confidence score, the actual rationale for the decision. Human review before anything escalates. When your compliance team asks "why did the agent do that," the answer is in the trace, not in a Slack thread from three weeks ago.
AGENT OBSERVATORY
Watch your agents work. In real time. What each one knows, what it tried, what it escalated, and why it escalated it. You wouldn't deploy a microservice to production without observability. Don't deploy agents to production without it either.
TOOLS AND MCP
Every connection your agent needs, managed in one place
Most teams discover MCP the same way. They install one server for GitHub. Another for Snowflake. Another for Jira. Each one local. Each one with its own credentials in its own config file. Six months later, the engineer who set them all up leaves and nobody else can run the agent.
That is the part of MCP nobody talks about. The protocol is elegant. Operating it across a team is a mess.
HOW WE HANDLE IT
LOCAL AND REMOTE, IN THE SAME CONFIG
Agents reach the tools they need whether the server runs as a subprocess on the engineer's laptop or as a hosted endpoint behind OAuth. Same config file. Same connection model. The agent does not care which one it is talking to and neither should you.
VENDOR MCPs WITHOUT THE VENDOR SPRAWL
When a vendor ships their own MCP server, plug it in. When you want a hosted version managed by us, use that instead. Mix the two. The agent sees one tool surface, not a dozen disconnected ones.
DATAMATES IS THE ENGINE UNDERNEATH
Datamates is our MCP engine. It validates every connection per tool, stores credentials in one place instead of scattered across config files, and exposes a clean CRUD interface for managing connections across your team. It is what turns MCP from a single-developer experiment into something a data org can actually run.
KNOWLEDGE HUB CONTEXT COMES WITH IT
Confluence pages. Google Docs. Notion. The agent gets the same business context your engineers do, through the same connection layer that handles the tools. So when the agent is changing fct_revenue, it can read the PRD that explains why the metric was defined that way.
SKILLS
The compiled engines that make agents reliable
A general coding agent will write you SQL that looks plausible. Sometimes it joins on the wrong key. Sometimes it traces lineage by guessing. Most of the time it is right. The problem is the times it is not.
The fix is not a better prompt. It is a layer of compiled, deterministic tools that sits outside the LLM. The LLM reasons. The engines validate.
WHAT'S IN THE TOOLKIT
SQL
Ten tools built on a real SQL parser. Static analysis against 19 anti-pattern rules with confidence scoring. Translation across Snowflake, BigQuery, Databricks, Redshift, Postgres, MySQL, SQL Server, and DuckDB. Optimization, formatting, diffing, fixing, explaining.
100% F1 on 1,077 queries, zero false positives.
COLUMN-LEVEL LINEAGE
Trace every column from source to target through arithmetic, aliases, joins, and CTEs. Confidence drops when the agent sees SELECT *, Jinja templates, or unqualified tables, so it knows when to trust the answer.
100% edge-match on 500 queries.
SCHEMA, DBT, WAREHOUSE, FINOPS
Live schema indexing without dumping context. dbt manifest parsing and verified dbt build. Warehouse connectivity and query history. FinOps surfaces query cost and right-sizing on real workloads, not a dashboard scrape.
MEMORY AND CUSTOM
State that survives long sessions. Bring your own tools and the agent treats them with the same compile-and-validate guarantees as the built-ins.
INFRASTRUCTURE
What agents run on
The warehouse vendors will tell you to run your agents inside their warehouse. Each of them has rebuilt their stack and renamed it agentic infrastructure.
That is not what an agent needs. An agent reasoning over data needs an environment where it can actually do the work. Spin up the runtime. Run the transformation against real data. Execute the tests. Verify the output. All before anything touches production. And it has to work across the stack you actually run, not just one warehouse.
SANDBOXES FOR THE MODERN DATA STACK
Provisioned, isolated environments with the runtimes your team already uses. dbt. Airflow. DuckDB. Trino. Spun up on our hardware, ready in seconds. Pair them with zero-copy clones of your warehouse and the agent runs against your real data, at production scale, without duplicating a byte. The work happens in the sandbox, the tests pass or fail in the sandbox, and you see the result before any of it reaches production. Not a simulation. A real environment, with real runtimes, on real data.
BRING YOUR OWN LLM, OR USE OURS
35+ providers. Anthropic, OpenAI, Google, AWS Bedrock, Azure, Ollama, the lot. Use what your security team already approved. Or use the Altimate LLM Gateway and we route across Sonnet 4.6, Opus 4.6, GPT-5.4, and more, picking the right model for the task. Either way, no model lock-in.
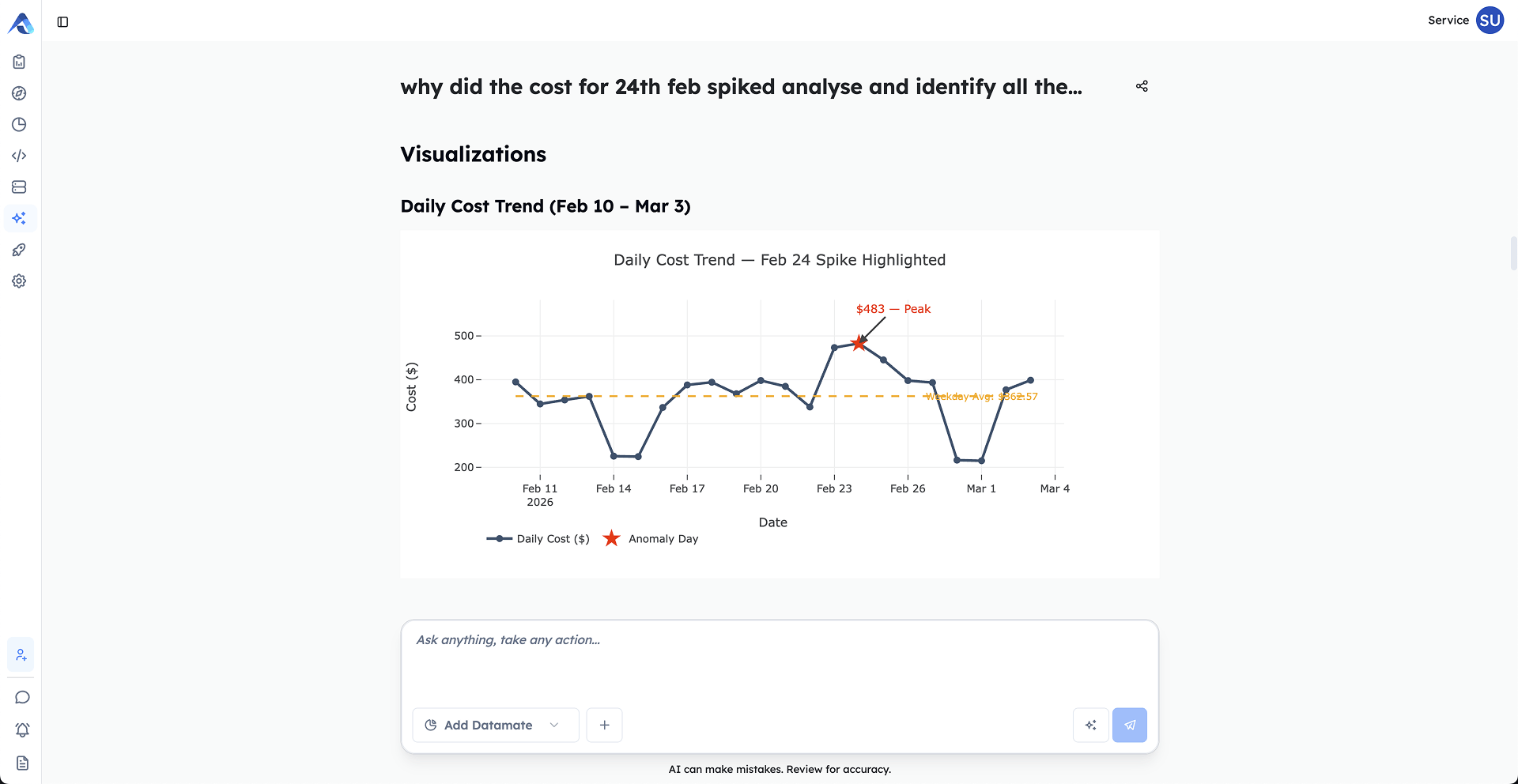
YOUR ENTIRE DATA STACK, IN ONE CONVERSATION.
Multi-agent AI across every tool in your stack
Studio is a specialized, multi-agent AI solution within the dbt Power User platform that enables users to interact with their entire data stack using natural language. Designed to overcome the limitations of traditional AI tools (which often return siloed, incomplete answers). Studio provides context-rich, comprehensive analysis across platforms and technologies including Snowflake, dbt, Tableau, Databricks, Airflow, and GitHub.
WORKS WITH YOUR STACK.
DATA PLATFORMS
ORCHESTRATION
BI & ANALYTICS
DEV TOOLS